Voice Conversion using GANs: An Extensive Review
For my project on code-mixed speech recognition with Prof. Preethi Jyothi, I did a literature review of voice conversion and found a lot of recent papers that used GANs for the problem. So I decided to write this post to summarize my review. I’ve also attached the slides and references I used in my group meeting at the end of this post.
Back in 2015, before GANs became popular for conversion problems, voice conversion models were trained for a particular target speaker and models were trained simply on regression loss. One good example is Lifa et al, 2015 where a deep BiLSTM network is used. They use STRAIGHT vocoder system to convert an utterance into 3 types of features viz. Mel-cepstral coefficients, aperiodicity measures, and $\log F_0$. Only the Mel-cepstral coefficients are transformed by BiLSTM for voice conversion. $\log F_0$ is linearly transformed using input speaker information and aperiodicity measures were simply forwarded to the synthesis system. The synthesis system took the transformed Mel-cepstral coefficients, aperiodicity measures and transformed $log F_0$ to generate output utterance. This system had several limitations including a single target speaker and need for parallel utterances which also had to be aligned using dynamic-time warping.
Before GANs were used for voice conversion, they were explored in the image domain, very notably by Zhu et al, 2017 and Kim et al, 2017. In Zhu et al, 2017, the idea of cycle-consistency loss is introduced which makes the whole thing possible. It is best explained from the figure shown below from the same paper.
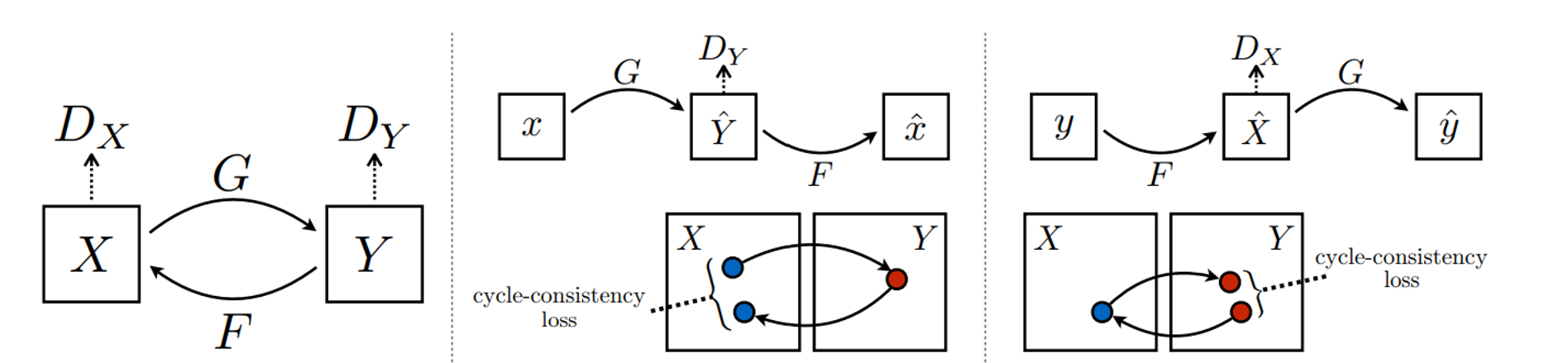
The idea is that there are two transformation networks $G$ and $F$, which transform from domain $X$ to $Y$ and $Y$ to $X$ respectively. In addition to the discriminative loss for real-fake classification, a consistency loss is used to ensure that $\hat{x} = F(G(x))$ is close to $x$ itself and $\hat{y} = G(F(y)$ is close to $y$ itself. The idea is totally life-changing! In case one is not impressed enough by the elegance of this idea, their mind will surely be blown away by the amazing results they’ve managed to achieve. An example from the paper is shown below where paintings from different painters were treated as different domains. Even if these results don’t satisfy you (who are you?), think about the big advantage that this model has: there is no need for parallel data. Just get a set of images from different domains, and transform them to impress your friends.
![]()
The idea proposed in Kim et al, 2017 is very similar except that they use it to find relationships among datapoints different domains. An example is shown below where the model learns to identify the orientation of the input image of a chair and give out an image of a car with the same orientation.
![]()
Another example shown below is for the transformation between a male face and a female face.
![]()
Extending these ideas to voice conversion is pretty straightforward. Kaneko et al, 2017 used the same idea of cycle-consistency loss for training a voice conversion system where they treated two different speakers as two domains. For details on their gated-CNN based model and how they use features from WORLD vocoder, one should refer to the paper. They have also provided samples here. Another very similar work is by Fang et al, 2018 where they’ve only transformed the lower order Mel-cepstrum using the GAN and copied the higher-order information for synthesis owing to the argument that speaker-specific information is only present in lower-order cepstrum.
Both of the above systems still have the disadvantage that only a pair of speakers can be used for training and inference in voice conversion. This was resolved by Kameoka et al, 2018 in their model called the StarGAN. This model has 3 parts: a generator (or more aptly called a transformer), a discriminator and a domain classifier. Here the generator and discriminator are conditioned on the domain by an additional input specifying the speaker. The simplest one to train is the classifier which is trained on real data to predict the domain of the input, or simply the speaker in case of voice conversion. The discriminator is, as usual, trained to identify real and fake data points. The loss for training generator has four terms with scaling parameters: an adversarial loss to fool discriminator, a domain classifier loss to ensure that output belongs to the domain the generator is conditioned on, a cyclic loss to ensure reliable conversion and an identity loss for identity conversion as a regularization. The demo can be seen here. They’ve also proposed other systems which can all be seen in the list given here. Very similar work is by Gao et al. where they’ve treated genders as the two domains.
The applications of the idea of cycle-consistency have been pretty impressive. Another important papers in this line is the work by Meng et al, 2018 on speech enhancement by learning noise using cycle-consistency GANs where the two domains are that of clean speech and noisy speech which is also an extension to their previous work in Meng et al, 2018 that didn’t use cycle-consistency.
Another very interesting application is presented by Tanaka et al, 2018 where they train a cycle-consistent GAN to make synthetic speech sound more natural. As one can guess, the two domains are that of synthetic speech and natural speech. They propose that this transformation can be used as an additional processing step in the vocoder pipelines after synthesis.
The rest of the post is about other related stuff that I found interesting. Since I’m talking about a generative model, it is important to mention that variational auto-encoders (VAEs) have also been used for voice conversion. An example is the work by Kameoka et al, 2018 where they maximize the mutual information between the output and domain in addition to the usual VAE loss. This maximization ensures that the encoder and decoder actually account for the conditioning on the domain and maximizes the usage of the bottleneck to preserve content. They show, using variational information maximization, that maximizing this mutual information reduces down to adding an auxiliary classifier and using to train VAE for minimizing classification loss. The demo can be seen here. One interested in their fully convolutional VAE for voice conversion should check out the paper in more detail.
Just to end this post on a positive note about GANs, I wish to mention two very popular papers that have explored the stability of GANs which have been applied in the image domain. I think that it would be very interesting to see this work in improving systems for voice conversion. The first one I wish to mention is the work by Karras et al, 2018 where they progressively increase layers in the network over time while ensuring a smooth change in dependence on new parameters, and fading in the new layers. The resolution of the image improves over each additional layer, finally leading to amazingly realistic fake images as the ones shown below.

Second is the paper by Mao et al, 2017 where they show that using least square error on discriminator output is more stable than using cross-entropy which is based on minimizing Jenson-Shannon divergence between the generator output distribution $P_G$ and the real data $P_D$. They show that minimizing the square error is instead equivalent to minimizing the Pearson $\chi^2$ divergence between $P_D + P_G$ and $2P_G$.
All the references and some further reading (which I’ll update over time) are given below. The slides from my presentation can be found here.
References
Voice conversion using deep Bidirectional Long Short-Term Memory based Recurrent Neural Networks
L. Sun et al., ICASSP 2015
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
J. Zhu et al., ICCV 2017
Learning to Discover Cross-Domain Relations with Generative Adversarial Networks
T. Kim et al., ICML 2017
Parallel-Data-Free Voice Conversion Using Cycle-Consistent Adversarial Networks
T. Kaneko et al., arXiv preprint arXiv:1711.11293, 2017
High-Quality Nonparallel Voice Conversion Based on Cycle-Consistent Adversarial Network
F. Fang et al., ICASSP 2018
StarGAN-VC: non-parallel many-to-many Voice Conversion Using Star Generative Adversarial Network
H. Kameoka et al., IEEE SLT 2018
Voice Impersonation using Generative Adversarial Networks
Y. Gao et al., arXiv preprint arXiv:1802.06840, 2018
Cycle-Consistent Speech Enhancement
Z. Meng et al., Interspeech 2018
Adversarial Feature-Mapping for Speech Enhancement
Z. Meng et al., Interspeech 2018
WaveCycleGAN: Synthetic-to-natural speech waveform conversion using cycle-consistent adversarial networks
K. Tanaka et al., arXiv preprint, 2018
ACVAE-VC: Non-parallel Many-to-many VC with Auxiliary Classifier VAE
H. Kameoka et al., arXiv preprint, 2018
Progressive Growing of GANs for Improved Quality, Stability and Variation
T. Karras et al., ICLR 2018
Least Squares Generative Adversarial Networks
X. Mao et al., ICCV 2017
Further Reading
CycleGAN-VC2: Improved CycleGAN-based non-parallel voice conversion
T. Kaneko et al., ICASSP 2019
WaveCycleGAN2: Time-domain neural post-filter for speech waveform generation
K. Tanaka et al., arXiv preprint arXiv:1904.02892, 2019
AUTOVC: Zero-Shot Voice Style Transfer with Only Autoencoder Loss
K. Qian et al., Proc. MLR, 2019
Leave a Comment